Avogadro 1 can auto-detect Molpro output files, and extract the vibrational modes even from very complicated output files. Please see this Molpro output file for an example.
UX with Avogadro 1:
Open Molpro output
Avogadro 1 opens it and immediately opens the vibrational modes panel
Very fast and straightforward.
UX with Avogadro 2:
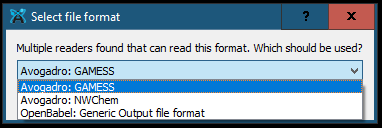
Open Molpro output
Avogadro 2 asks the user to choose which reader should be used
User has to choose “OpenBabel: Generic Output file format”, the other options offered do not work and fail semi-silently (explained below)
The geometry is loaded but no normal mode panel is displayed. It cannot be manually enabled either, as “Analysis → Vibrational modes” is grayed out.
User has to keep using Avogadro 1 for this purpose.
Very unpleasant UX…
To me this looks like a combination of multiple problems.
Avogadro should not offer the GAMESS and NWChem readers if the file looks like a Molpro output file, because they do not work for this purpose at all.
The GAMESS and NWChem readers are not sufficiently resilient against being used on unsuitable inputs, and fail silently. If I choose them, the file is opened and I get no error messages, but no actual data is loaded at all, not even the coordinates of the atoms. These readers should realize that they got a bad file, throw an error message (eg. “This file does not look like a GAMESS output file at all!”) and Avogadro should show the “Select file format” dialog again.
Imagine how confusing the current behaviour is to an undergrad who does not even know what GAMESS and NWChem is yet.
Fixing 1. would hide this issue, but I bet that something similar could happen to other output formats or under unforeseen circumstances, so predictable/graceful failure of the readers is preferred.
Avogadro 2 should be able to load normal modes from Molpro outputs somehow to be able to replace Avogadro 1. I have not looked into the source code, but this is something that got lost in the rewrite.
Thanks for the feedback. I agree 100% - there needs to be better “automagic” file handling.
The catch is that the code would need to read at least some of the file to do that. This is the concept behind Open Babel’s .out format reader, but it would need a bit of work in avogadrolibs to offer the same sort of feature.
It’s also a little complicated because you can install Python extensions… I’m generally using avogadro-cclib … so the code would need to decide if Avogadro internal code can handle it, or whether it should hand off to Open Babel or a Python script like cclib.
I appreciate the patch you just submitted. Yes, it’s a good point. I have to go check what code pops up that dialog and make it a bit smarter as you describe.
At the moment, Open Babel is using CML or SD files to exchange data with Avogadro2. Neither has support for spectra or vibrational modes. I need to write CJSON support into Open Babel.
In the meantime, I would suggest installing cclib into your Python environment and the avogadro-cclib extension. This should get you normal modes from Molpro for now.
There are probably reasons for this, but from a “naiive outsider” perspective I don’t get why there are three different file parsing backends. It looks like historical baggage.
Internal
Open Babel
CClib
At first glance the most straightforward approach would be to choose either Obabel or CClib, make it a hard dependency and remove IO code related to the other two. If Avogadro needs something that the chosen library cannot do, extend the library and send the patches upstream.
But of course easier said than done.
In this case, the “historical baggage” is that a lot of the core Avogadro2 code was funded by the US Department of Energy. Both NWChem and GAMESS are DOE-funded codes, and so these were important features.
Open Babel is already a hard dependency. But as you’ve noticed, that doesn’t mean it supports everything you might want (e.g., OB needs CJSON support).
I don’t get why there are three different file parsing backends.
I think the question is less “why are there different options” and more how to handle cases in which a file can be handled with different code.
The reason to add Python readers like avogadro-cclib is that users can parse formats and share script plugins without needing to wait for Open Babel (or Avogadro2) to “extend the library.”
That’s been a primary motivation in Avogadro2 – make it much easier to extend the core code with Python. Maybe extract from a hd5 archive or a particular group’s custom code. Case in point, one of my students contributed a patch for xtb to cclib. I’ll probably try to port this to openbabel too, but my group can already read xtb files directly in Avogadro2.
Fair points all around. Given how much extra functionality CClib adds to A2, would it be feasible to ship both CClib and the plugin in the Win64 installer? Probably not for nightly builds or CI artifacts, but for regular releases?
It would avoid the additional friction of having to explain “Oh you need to install Python 3.??, then install CClib, then install this A2 plugin to be able to read these file formats properly”.
Thanks, at the moment we are mostly fine with A1, aside from some minor annoyances it does what we need it to do, and when it does not we use wxMacMolPlt. But of course eventually I would like to be able to advise my colleagues to upgrade to A2.